The post AI Co-Pilots – The Redefining Office Productiveness Instruments appeared first on CreditLose.
]]>One of the compelling advantages of AI co-pilots in productiveness is their potential to adapt and study from particular person work patterns. In contrast to conventional software program that operates on predefined instructions, AI co-pilots analyze consumer habits, preferences, and even emotional cues to tailor their help. This personalization fosters an setting the place workers really feel understood and supported, in the end resulting in greater job satisfaction and engagement. Think about a digital assistant that not solely reminds you of deadlines but additionally understands whenever you’re confused or overwhelmed-and adjusts its assist accordingly.
This functionality permits groups scattered throughout totally different time zones and languages to have interaction seamlessly, fostering innovation and creativity. On this fast-paced world the place concepts should be shared shortly but successfully, these clever instruments turn out to be important allies in holding tasks aligned with out sacrificing high quality or cAI Co-Pilots are quickly reworking the way in which we have interaction with our every day duties, bringing a degree of effectivity and perception to the office that was beforehand unimaginable.
What Are AI Co-Pilots?
AI co-pilots signify a transformative step in how we strategy our every day duties. In contrast to conventional instruments that require express instructions, these clever assistants seamlessly combine into our workflows, anticipating our wants and suggesting proactive options. Think about having an assistant that not solely organizes your calendar but additionally intelligently prioritizes duties based mostly on upcoming deadlines and the intricacies of your projects-saving time and offering focus the place it is most wanted.
These good co-workers harness huge quantities of knowledge to reinforce decision-making processes, drawing insights from pattern evaluation and even emotional tones in emails for extra personalised interactions. Furthermore, AI co-pilots are designed for real-time collaboration; they will analyze staff dynamics, facilitate communication throughout departments, and guarantee everyone seems to be aligned with venture objectives. This newfound synergy between human creativity and machine effectivity might make the office extra productive and interesting, permitting workers to channel their vitality into modern problem-solving moderately than mundane activity administration.
Advantages of AI Co-Pilots in Productiveness
AI Co-Pilots remodel the panorama of office productiveness by performing as clever companions that improve particular person and staff capabilities. By automating repetitive duties, these digital assistants release useful time for workers to give attention to higher-value actions that require creativity and important considering. In consequence, professionals can shift their vitality from mere activity completion to ideation and strategic planning, fostering an setting the place innovation can flourish.
AI Co-Pilots present personalised insights pushed by huge information evaluation, serving to employees make knowledgeable selections shortly. For example, ongoing tasks can profit from real-time suggestions and adaptive recommendations tailor-made to particular workflows or challenges.
This streamlines processes and cultivates a tradition of steady studying and enchancment inside groups. As organizations embrace this collaborative strategy between people and machines, they’re seeing enhanced engagement ranges amongst workers who really feel supported of their roles-ultimately main to raised enterprise outcomes and a extra resilient workforce.
Key Options of Efficient AI Co-Pilots
One of the essential options of efficient AI co-pilots is their potential to study and adapt in real-time. In contrast to static instruments, a sturdy AI co-pilot constantly refines its understanding of consumer preferences, workflows, and venture nuances. This adaptability promotes a personalised expertise that may result in substantial enhancements in effectivity and creativity. For instance, as an AI co-pilot observes how customers sort out complicated duties over time, it begins to counsel options and methods tailor-made particularly to the person’s working style-transforming mere recommendations into actionable insights.
One other compelling attribute is seamless integration with current software program ecosystems. An efficient AI co-pilot would not simply function as a standalone instrument; it turns into an intrinsic a part of the workflow by harmonizing with purposes throughout numerous platforms. This fluid integration helps reduce friction factors that always disrupt productiveness, permitting professionals to pivot shortly between duties with out shedding momentum. Furthermore, proficient AI co-pilots make use of pure language processing capabilities that allow intuitive interaction-users can talk their wants conversationally moderately than by complicated instructions or technical jargon, additional enhancing consumer engagement and satisfaction.
Integrating AI Co-Pilots into Workflow
Integrating AI Co-Pilots into current workflows transforms how groups strategy problem-solving and innovation. Think about having an clever associate that not solely assists with routine duties but additionally analyzes information patterns, gives actionable insights, and suggests inventive options in real-time. This dynamic partnership permits workers to give attention to strategic considering moderately than getting slowed down by mundane particulars. Organizations can improve decision-making processes and catalyze sooner venture completions by fostering a collaborative setting the place human instinct meets AI precision.
The seamless integration of those AI instruments opens up new avenues for ongoing studying and adaptation. Staff are inspired to leverage co-pilots for coaching functions, thus turning each activity right into a teachable second that contributes to skilled development. The flexibility to work together intuitively with these programs fosters a tradition of experimentation; groups really feel empowered to iterate quickly with out concern of failure whereas staying aligned with organizational objectives. As this know-how matures, it empowers people not simply as customers however as co-creators of their work environments-challenging conventional hierarchies and paving the way in which for modern collaborations throughout numerous sectors.
Overcoming Challenges with AI Implementation
AI implementation can usually really feel like navigating a labyrinth crammed with unexpected challenges, but every impediment presents a chance for development and innovation. One of the vital hurdles is resistance from workers who could concern that AI might change their jobs. Overcoming this mindset requires clear communication about AI’s position as a co-pilot moderately than a replacement-demonstrating the way it can deal with mundane duties, liberating human employees to give attention to inventive problem-solving and strategic initiatives. By framing AI as an empowering instrument that enhances particular person strengths, organizations can foster an setting ripe for collaboration.
Efficient coaching and assist programs are essential in easing the transition in the direction of AI integration. Corporations should spend money on steady teaching programs that not solely educate workers how one can use these superior instruments but additionally assist them perceive their implications inside their particular roles. Emphasizing hands-on expertise by real-world purposes permits customers to see the sensible advantages firsthand, reworking apprehension into enthusiasm. When groups witness tangible enhancements in productiveness and effectivity pushed by these applied sciences, they turn out to be extra engaged champions of change moderately than reluctant contributors; thus, cultivating a office tradition that eagerly embraces the evolving panorama of productiveness instruments.
Actual-World Examples of Profitable Use Circumstances
Within the finance sector, firms like JPMorgan Chase have leveraged AI Co-Pilots to reinforce their funding evaluation. Their proprietary instrument, COiN (Contract Intelligence), processes huge quantities of authorized paperwork in seconds, figuring out dangers and alternatives which may take human analysts days to uncover. By harnessing pure language processing, these AI programs not solely streamline workflow but additionally equip groups with deeper insights, permitting them to give attention to strategic decision-making moderately than routine duties.
Equally, within the healthcare business, Radiologists at a number one hospital are turning to AI-powered imaging instruments that act as co-pilots throughout analysis. These programs help practitioners by highlighting abnormalities in scans and suggesting potential areas of concern based mostly on earlier circumstances. This collaboration reduces diagnostic errors and accelerates affected person care whereas enabling well being professionals to channel their experience into complicated evaluations the place human instinct stays irreplaceable. Such purposes spotlight how AI Co-Pilots can considerably uplift productiveness by refining workflow efficiencies throughout various sectors-proving that innovation is not only about substitute however complementing human capabilities.
Future Tendencies in AI Office Instruments
As we transfer additional into the digital age, AI office instruments are evolving quickly from easy automation to stylish co-pilots that improve human capabilities. One rising pattern is the combination of emotional intelligence in AI programs, enabling them to not solely analyze information but additionally perceive and reply to worker sentiments. This might manifest as clever suggestions mechanisms or digital assistants that personalize interactions based mostly on temper recognition, successfully making a extra empathetic office environment.
Moreover, the rise of hyper-personalization will redefine how duties and workflows are managed inside organizations. Future AI instruments could harness in depth information analytics to offer tailor-made methods for particular person workers in response to their work kinds and productiveness patterns. Think about superior algorithms suggesting optimum venture timelines or personalized coaching modules that match your studying pace-all geared toward unleashing creativity whereas minimizing burnout. This shift towards individualized assist will lead companies not simply in the direction of elevated effectivity but additionally foster a tradition the place innovation thrives by collaboration between human perception and machine intelligence.
Suggestions for Maximizing AI Co-Pilot Potential
To completely leverage the potential of AI co-pilots, it is important to embrace a mindset of collaboration moderately than merely viewing them as instruments. Begin by integrating these programs not simply into your workflows but additionally into your decision-making processes. For example, when brainstorming concepts or tackling complicated issues, use the AI’s functionality to research information tendencies and generate different views. This may result in extra modern options that capitalize on each human instinct and machine-based insights.
One other highly effective technique is personalizing interactions along with your AI co-pilot. Make investments time in coaching the system by offering suggestions on its outputs; over time, this can refine its understanding of your preferences and distinctive work type, enhancing its relevance and effectiveness in duties. Furthermore, make the most of options comparable to activity administration and reminders proactively-this helps preserve a streamlined workflow with out shedding sight of long-term objectives. By treating AI as an clever associate moderately than a competitor, workers can unlock productiveness ranges beforehand thought unattainable whereas fostering creativity by various collaboration avenues.
Conclusion: The Way forward for Office Effectivity
As we gaze into the way forward for office effectivity, it is clear that AI co-pilots usually are not merely enhancing productiveness; they’re basically reworking how we strategy our work. The mixing of those clever programs guarantees a workforce that operates with unprecedented pace and precision, permitting groups to give attention to inventive problem-solving moderately than mundane duties. Think about a panorama the place AI seamlessly identifies bottlenecks, gives actionable insights, and suggests optimum workflows tailor-made to particular person strengths and weaknesses. This shift will empower professionals to harness their distinctive abilities extra successfully whereas decreasing burnout.
Enhanced by real-time information sharing and predictive analytics, groups can work collectively in methods beforehand deemed impossible-bridging geographical divides effortlessly by automated scheduling and digital brainstorming periods pushed by AI insights. On this new paradigm, workplaces might turn out to be bastions of innovation powered not simply by human mind however augmented by AI capabilities that gasoline creativity and flexibility. Finally, those that embrace this synergy will thrive in an period outlined by steady transformation, redefining what productiveness actually means within the fashionable workspace.
The put up AI Co-Pilots – The Redefining Office Productiveness Instruments appeared first on Datafloq.
[ad_2]
The post AI Co-Pilots – The Redefining Office Productiveness Instruments appeared first on CreditLose.
]]>The post Learn how to Construct a Chatbot Utilizing Retrieval Augmented Era (RAG) appeared first on CreditLose.
]]>Overview
On this information, you’ll:
- Achieve a foundational understanding of RAG, its limitations and shortcomings
- Perceive the thought behind Self-RAG and the way it might result in higher LLM efficiency
- Learn to make the most of OpenAI API (GPT-4 mannequin) with the Rockset API suite (vector database) together with LangChain to carry out RAG (Retrieval-Augmented Era) and create an end-to-end net utility utilizing Streamlit
- Discover an end-to-end Colab pocket book which you can run with none dependencies in your native working system: RAG-Chatbot Workshop
Massive Language Fashions and their Limitations
Massive Language Fashions (LLMs) are educated on massive datasets comprising textual content, pictures, or/and movies, and their scope is usually restricted to the matters or info contained throughout the coaching information. Secondly, as LLMs are educated on datasets which are static and sometimes outdated by the point they’re deployed, they’re unable to supply correct or related details about latest developments or traits. This limitation makes them unsuitable for situations the place real-time up-to-the-minute info is important, comparable to information reporting, and so forth.
As coaching LLMs is kind of costly, with fashions comparable to GPT-3 costing over $4.6 million, retraining the LLM is usually not a possible choice to deal with these shortcomings. This explains why real-time situations, comparable to investigating the inventory market or making suggestions, can’t rely on or make the most of conventional LLMs.
Attributable to these aforementioned limitations, the Retrieval-Augmented Era (RAG) strategy was launched to beat the innate challenges of conventional LLMs.
What’s RAG?
RAG (Retrieval-Augmented Era) is an strategy designed to reinforce the responses and capabilities of conventional LLMs (Massive Language Fashions). By integrating exterior data sources with the LLM, RAG tackles the challenges of outdated, inaccurate, and hallucinated responses typically noticed in conventional LLMs.
How RAG Works
RAG extends the capabilities of an LLM past its preliminary coaching information by offering extra correct and up-to-date responses. When a immediate is given to the LLM, RAG first makes use of the immediate to tug related info from an exterior information supply. The retrieved info, together with the preliminary immediate, is then handed to the LLM to generate an knowledgeable and correct response. This course of considerably reduces hallucinations that happen when the LLM has irrelevant or partially related info for a sure topic.
Benefits of RAG
- Enhanced Relevance: By incorporating retrieved paperwork, RAG can produce extra correct and contextually related responses.
- Improved Factual Accuracy: Leveraging exterior data sources helps in decreasing the probability of producing incorrect info.
- Flexibility: May be utilized to varied duties, together with query answering, dialogue methods, and summarization.
Challenges of RAG
- Dependency on Retrieval High quality: The general efficiency is closely depending on the standard of the retrieval step.
- Computational Complexity: Requires environment friendly retrieval mechanisms to deal with large-scale datasets in real-time.
- Protection Gaps: The mixed exterior data base and the mannequin’s parametric data won’t at all times be adequate to cowl a selected subject, resulting in potential mannequin hallucinations.
- Unoptimized Prompts: Poorly designed prompts can lead to combined outcomes from RAG.
- Irrelevant Retrieval: Situations the place retrieved paperwork don’t comprise related info can fail to enhance the mannequin’s responses.
Contemplating these limitations, a extra superior strategy known as Self-Reflective Retrieval-Augmented Era (Self-RAG) was developed.
What’s Self-RAG?
Self-RAG builds on the rules of RAG by incorporating a self-reflection mechanism to additional refine the retrieval course of and improve the language mannequin’s responses.
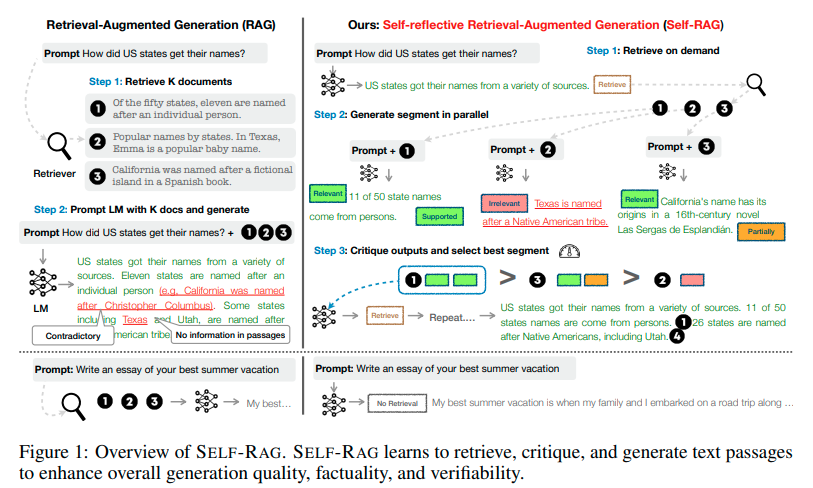
Key Options of Self-RAG
- Adaptive Retrieval: Not like RAG’s mounted retrieval routine, Self-RAG makes use of retrieval tokens to evaluate the need of knowledge retrieval. It dynamically determines whether or not to have interaction its retrieval module primarily based on the precise wants of the enter, intelligently deciding whether or not to retrieve a number of occasions or skip retrieval altogether.
- Clever Era: If retrieval is required, Self-RAG makes use of critique tokens like IsRelevant, IsSupported, and IsUseful to evaluate the utility of the retrieved paperwork, guaranteeing the generated responses are knowledgeable and correct.
- Self-Critique: After producing a response, Self-RAG self-reflects to guage the general utility and factual accuracy of the response. This step ensures that the ultimate output is best structured, extra correct, and adequate.
Benefits of Self-RAG
- Greater High quality Responses: Self-reflection permits the mannequin to establish and proper its personal errors, resulting in extra polished and correct outputs.
- Continuous Studying: The self-critique course of helps the mannequin to enhance over time by studying from its personal evaluations.
- Better Autonomy: Reduces the necessity for human intervention within the refinement course of, making it extra environment friendly.
Comparability Abstract
- Mechanism: Each RAG and Self-RAG use retrieval and technology, however Self-RAG provides a critique and refinement step.
- Efficiency: Self-RAG goals to supply larger high quality responses by iteratively enhancing its outputs by self-reflection.
- Complexity: Self-RAG is extra complicated as a result of extra self-reflection mechanism, which requires extra computational energy and superior methods.
- Use Instances: Whereas each can be utilized in comparable functions, Self-RAG is especially helpful for duties requiring excessive accuracy and high quality, comparable to complicated query answering and detailed content material technology.
By integrating self-reflection, Self-RAG takes the RAG framework a step additional, aiming to reinforce the standard and reliability of AI-generated content material.
Overview of the Chatbot Utility
On this tutorial, we might be implementing a chatbot powered with Retrieval Augmented Era. Within the curiosity of time, we’ll solely make the most of conventional RAG and observe the standard of responses generated by the mannequin. We’ll hold the Self-RAG implementation and the comparisons between conventional RAG and self-RAG for a future workshop.
We’ll be producing embeddings for a PDF known as Microsoft’s annual report with a purpose to create an exterior data base linked to our LLM to implement RAG structure. Afterward, we’ll create a Question Lambda on Rockset that handles the vectorization of textual content representing the data within the report and retrieval of the matched vectorized phase(s) of the doc(s) along side the enter person question. On this tutorial, we’ll be utilizing GPT-4 as our LLM and implementing a operate in Python to attach retrieved info with GPT-4 and generate responses.
Steps to construct the RAG-Powered Chatbot utilizing Rockset and OpenAI Embedding
Step 1: Producing Embeddings for a PDF File
The next code makes use of Openai’s embedding mannequin together with Python’s ‘pypdf library to interrupt the content material of the PDF file into chunks and generate embeddings for these chunks. Lastly, the textual content chunks are saved together with their embeddings in a JSON file for later.
from openai import OpenAI
import json
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
shopper = OpenAI(api_key="sk-************************")
def get_embedding(textual content):
response = shopper.embeddings.create(
enter=[text],
mannequin="text-embedding-3-small"
)
embedding = response.information[0].embedding
return embedding
reader = PdfReader("/content material/microsoft_annual_report_2022.pdf")
pdf_texts = [p.extract_text().strip() for p in reader.pages if p.extract_text()]
character_splitter = RecursiveCharacterTextSplitter(
separators=["nn", "n"],
chunk_size=1000,
chunk_overlap=0
)
character_split_texts = character_splitter.split_text('nn'.be a part of(pdf_texts))
data_for_json = []
for i, chunk in enumerate(character_split_texts, begin=1):
embedding = get_embedding(chunk) # Use OpenAI API to generate embedding
data_for_json.append({
"chunk_id": str(i),
"textual content": chunk,
"embedding": embedding
})
# Writing the structured information to a JSON file
with open("chunks_with_embeddings.json", "w") as json_file:
json.dump(data_for_json, json_file, indent=4)
print(f"Whole chunks: {len(character_split_texts)}")
print("Embeddings generated and saved in chunks_with_embeddings.json")
Step 2: Create a brand new Assortment and Add Information
To get began on Rockset, sign-up totally free and get $300 in trial credit. After making the account, create a brand new assortment out of your Rockset console. Scroll to the underside and select File Add below Pattern Information to add your information.

You will be directed to the next web page. Click on on Begin.

Click on on the file Add button and navigate to the file you wish to add. We’ll be importing the JSON file created in step 1 i.e. chunks_with_embeddings.json. Afterward, you’ll evaluate it below Supply Preview.
Notice: In observe, this information would possibly come from a streaming service, a storage bucket in your cloud, or one other related service built-in with Rockset. Study extra in regards to the connectors supplied by Rockset right here.

Now, you will be directed to the SQL transformation display screen to carry out transformations or characteristic engineering as per your wants.
As we do not wish to apply any transformation now, we’ll transfer on to the following step by clicking Subsequent.

Now, the configuration display screen will immediate you to decide on your workspace together with the Assortment Title and several other different assortment settings.
It is best to title the gathering after which proceed with default configurations by clicking Create.

Finally, your assortment might be arrange. Nevertheless, there could also be a delay earlier than the Ingest Standing switches from Initializing to Linked.
After the standing has been up to date, you should use Rockset’s question device to entry the gathering by the Question this Assortment button situated within the top-right nook of the picture beneath.

Step 3: Producing Question Lambda on Rockset
Question lambda is an easy parameterized SQL question that’s saved in Rockset so it may be executed from a devoted REST endpoint after which utilized in varied functions. In an effort to present clean info retrieval on the run to the LLM, we’ll configure the Question Lambda with the next question:
SELECT
chunk_id,
textual content,
embedding,
APPROX_DOT_PRODUCT(embedding, VECTOR_ENFORCE(:query_embedding, 1536, 'float')) as similarity
FROM
workshops.external_data d
ORDER BY similarity DESC
LIMIT :restrict;
This parameterized question calculates the similarity utilizing APPROXDOTPRODUCT between the embeddings of the PDF file and a question embedding supplied as a parameter query_embedding.
We are able to discover probably the most comparable textual content chunks to a given question embedding with this question whereas permitting for environment friendly similarity search throughout the exterior information supply.
To construct this Question Lambda, question the gathering made in step 2 by clicking on Question this assortment and pasting the parameterized question above into the question editor.

Subsequent, add the parameters one after the other to run the question earlier than saving it as a question lambda.


Click on on Save within the question editor and title your question lambda to make use of it from endpoints later.

At any time when this question is executed, it is going to return the chunk_id, textual content, embedding, and similarity for every file, ordered by the similarity in descending order whereas the LIMIT clause will restrict the whole variety of outcomes returned.
If you would like to know extra about Question lambdas, be at liberty to learn this weblog submit.
Step 4: Implementing RAG-based chatbot with Rockset Question Lambda
We’ll be implementing two features retrieve_information and rag with the assistance of Openai and Rockset APIs. Let’s dive into these features and perceive their performance.
- Retrieve_information
This operate queries the Rockset database utilizing an API key and a question embedding generated by Openai’s embedding mannequin. The operate connects to Rockset, executes a pre-defined question lambda created in step 2, and processes the outcomes into a listing object.
import rockset
from rockset import *
from rockset.fashions import *
rockset_key = os.environ.get('ROCKSET_API_KEY')
area = Areas.usw2a1
def retrieve_information( area, rockset_key, search_query_embedding):
print("nRunning Rockset Queries...")
rs = RocksetClient(api_key=rockset_key, host=area)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="newest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for file in api_response["results"]:
record_data = {
"textual content": file['text']
}
records_list.append(record_data)
return records_list
- RAG
The rag operate makes use of Openai’s chat.completions.create to generate a response the place the system is instructed to behave as a monetary analysis assistant. The retrieved paperwork from retrieve_information are fed into the mannequin together with the person’s unique question. Lastly, the mannequin then generates a response that’s contextually related to the enter paperwork and the question thereby implementing an RAG stream.
from openai import OpenAI
shopper = OpenAI()
def rag(question, retrieved_documents, mannequin="gpt-4-1106-preview"):
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information"
},
{"role": "user", "content": f"Question: {query}. n Information: {retrieved_documents}"}
]
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=messages,
)
content material = response.decisions[0].message.content material
return content material
Step 5: Setting Up Streamlit for Our Chatbot
To make our chatbot accessible, we’ll wrap the backend functionalities right into a Streamlit utility. Streamlit gives a hassle-free front-end interface, enabling customers to enter queries and obtain responses straight by the online app.
The next code snippet might be used to create a web-based chatbot utilizing Streamlit, Rockset, and OpenAI’s embedding mannequin. Here is a breakdown of its functionalities:
- Streamlit Tittle and Subheader: The code begins organising the webpage configuration with the title “RockGPT” and a subheader that describes the chatbot as a “Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI“.
- Consumer Enter: It prompts customers to enter their question utilizing a textual content enter field labeled “Enter your question:“.
-
Submit Button and Processing:
- When the person presses the ‘Submit‘ button, the code checks if there’s any person enter.
- If there’s enter, it proceeds to generate an embedding for the question utilizing OpenAI’s embeddings.create operate.
- This embedding is then used to retrieve associated paperwork from a Rockset database by the getrsoutcomes operate.
-
Response Era and Show:
- Utilizing the retrieved paperwork and the person’s question, a response is generated by the rag operate.
- This response is then displayed on the webpage formatted as markdown below the header “Response:“.
- No Enter Dealing with: If the Submit button is pressed with none person enter, the webpage prompts the person to enter a question.
import streamlit as st
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your question:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the person question
embedding_response = shopper.embeddings.create(enter=user_query, mannequin="text-embedding-3-small")
search_query_embedding = embedding_response.information[0].embedding
# Retrieve paperwork from Rockset primarily based on the embedding
records_list = get_rs_results(area, rockset_key, search_query_embedding)
# Generate a response primarily based on the retrieved paperwork
response = rag(user_query, records_list)
# Show the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a question to get a response.")
Here is how our Streamlit utility will initially seem within the browser:

Under is the whole code snippet for our Streamlit utility, saved in a file named app.py. This script does the next:
- Initializes the OpenAI shopper and units up the Rockset shopper utilizing API keys.
- Defines features to question Rockset with the embeddings generated by OpenAI, and to generate responses utilizing the retrieved paperwork.
- Units up a easy Streamlit UI the place customers can enter their question, submit it, and look at the chatbot’s response.
import streamlit as st
import os
import rockset
from rockset import *
from rockset.fashions import *
from openai import OpenAI
# Initialize OpenAI shopper
shopper = OpenAI()
# Set your Rockset API key right here or fetch from surroundings variables
rockset_key = os.environ.get('ROCKSET_API_KEY')
area = Areas.usw2a1
def get_rs_results(area, rockset_key, search_query_embedding):
"""
Question the Rockset database utilizing the supplied embedding.
"""
rs = RocksetClient(api_key=rockset_key, host=area)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="newest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for file in api_response["results"]:
record_data = {
"textual content": file['text']
}
records_list.append(record_data)
return records_list
def rag(question, retrieved_documents, mannequin="gpt-4-1106-preview"):
"""
Generate a response utilizing OpenAI's API primarily based on the question and retrieved paperwork.
"""
messages = [
{"role": "system", "content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information."},
{"role": "user", "content": f"Question: {query}. n Information: {retrieved_documents}"}
]
response = shopper.chat.completions.create(
mannequin=mannequin,
messages=messages,
)
return response.decisions[0].message.content material
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Era primarily based Chatbot utilizing Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your question:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the person question
embedding_response = shopper.embeddings.create(enter=user_query, mannequin="text-embedding-3-small")
search_query_embedding = embedding_response.information[0].embedding
# Retrieve paperwork from Rockset primarily based on the embedding
records_list = get_rs_results(area, rockset_key, search_query_embedding)
# Generate a response primarily based on the retrieved paperwork
response = rag(user_query, records_list)
# Show the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a question to get a response.")
Now that all the pieces is configured, we are able to launch the Streamlit utility and question the report utilizing RAG, as proven within the image beneath:

By following the steps outlined on this weblog submit, you have realized how you can arrange an clever chatbot or search assistant able to understanding and responding successfully to your queries.
Do not cease there—take your tasks to the following degree by exploring the wide selection of functions doable with RAG, comparable to superior question-answering methods, conversational brokers and chatbots, info retrieval, authorized analysis and evaluation instruments, content material suggestion methods, and extra.
Cheers!!!
[ad_2]
The post Learn how to Construct a Chatbot Utilizing Retrieval Augmented Era (RAG) appeared first on CreditLose.
]]>The post North Drives Tens of millions in Worth by Governing Snowflake with Atlan appeared first on CreditLose.
]]>Combining Atlan, Snowflake, and Sigma to Democratize Entry to Properly-governed Knowledge
At a Look
- North, a number one funds resolution supplier processing over $100 billion in annual transactions, aimed to enhance information discovery and governance atop their Snowflake- and Sigma-powered fashionable information stack
- Adopting Atlan as their energetic metadata platform, North has since achieved end-to-end visibility of 225,000 information belongings, securing delicate information, and growing adoption of self-service analytics
- In lower than a yr, their group is projecting $1.4mm in annual effectivity beneficial properties and a 200% progress in Sigma adoption whereas realizing a 700% improve in tagged Snowflake belongings which has contributed to mitigating hundreds of thousands of {dollars} in danger

For over 30 years, North has established itself as a number one funds resolution supplier, now processing over $100 billion in transactions yearly. With a various portfolio of over 20 manufacturers and subsidiaries, they assist a broad vary of cost wants, supporting brick-and-mortar and on-line shops by means of cost gateways, cellular options, and extra. Dedicated to serving industries that span eating places to authorities entities, North goals to be the simplest end-to-end funds supplier to do enterprise with.
With an unlimited information property comprising 225,000 belongings, totaling 41 terabytes on Snowflake, the duty of managing and governing North’s information belongs to Daniel Dowdy, Vice President of Knowledge Analytics & Governance, serving for 13 years on the firm. Becoming a member of Atlan at Snowflake Summit 2024, Daniel shared his group’s journey, constructing and governing a contemporary information stack that helps each inner information shoppers and their flagship merchandise.
What do 20 subsidiaries and types, and 100,000+ retailers, imply for our group? It means we’ve plenty of information. We use that information to assist a few of our hottest merchandise.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance

North’s flagship choices, Payanywhere and Funds Hub, equip retailers with something from {hardware} and software program, to safe on-line portals, simplifying the complexities of funds for retailers.
Funds Hub, a complete funds and operations platform, serves as a command middle for every thing from transaction monitoring and reporting to stock administration and fraud safety. To ship important, transaction-level reporting to their prospects, North depends on Snowflake.
“We make the most of Snowflake for each of those on the backend to supply close to real-time reporting and transaction-level reporting to our prospects,” Daniel shared. “With out Snowflake, this simply wouldn’t be doable.”
Earlier than Snowflake, Knowledge Silos

Earlier than Snowflake, North struggled with unchecked and unclear information. Easy duties like pulling uncooked information or producing experiences might take days and even weeks, hindered by ETL bottlenecks and information silos scattered throughout a number of servers and databases, or Excel recordsdata circulated throughout the group.
As soon as a file goes out, that information is already stale. To not point out that when that file leaves you, customers can then modify it and make their very own supply of fact. So, you’re fighting a number of sources of the reality.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
The shortage of a single supply of fact difficult efforts to drive belief in North’s information, and with out clear lineage and governance, controlling that information as soon as it left their fingers proved tough.
After Snowflake + Sigma, Correct, Actual-time Knowledge

In 2019, North adopted Snowflake as their enterprise information lake, considerably enhancing their information science, analytics, and reporting capabilities. By shifting from outdated batch processing to real-time CDC options, their group traded cumbersome ETL workflows and embraced the effectivity of contemporary ELT processes.
“We went from a ‘Knowledge Desert,’ the place retrieving data took days, to an oasis the place information was obtainable in actual time, and we might question it in seconds,” stated Daniel.
Whereas Snowflake represented a big leap ahead within the availability and reliability of knowledge, Daniel’s group have been nonetheless accountable for fielding easy requests for information entry. To scale back this workload, and to make information much more accessible to a rising variety of shoppers, their group launched Sigma, a enterprise intelligence software that empowers customers to independently entry, analyze, and visualize information, providing essential data in a self-service method.

With its acquainted, Excel-like interface, enterprise customers shortly embraced Sigma, leading to a skyrocketing adoption charge, with annual consumer progress now exceeding 200%.
Starting with 10 customers in 2019, we now have over 350 customers in Sigma, with an annual progress charge of greater than 200% year-over-year. Now, Sigma is our self-service analytics platform, and it’s taken plenty of burden off our information group.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance

North has since engineered a contemporary information stack, organising strong pipelines that seamlessly ingest and replicate information from numerous sources like Oracle, MySQL, Salesforce, and S3. This wealth of knowledge is then channeled into highly effective instruments akin to Qlik, Snowpipe, and Kafka, all converging inside Snowflake.
As the amount and number of information grew, so did the demand for entry, shifting the problem from mere information accessibility to the extra advanced points of knowledge governance and discovery.
“What grew to become the issue was methods to discover the information, and methods to govern it properly,” Daniel shared. “Atlan grew to become the central level addressing all of those issues.”
Unlocking Snowflake and Sigma with Atlan
Connecting to over 225,000 information belongings inside Snowflake and Sigma took simply hours with Atlan, driving unprecedented visibility on a big scale.
“After partnering with Atlan, it took most likely a few hours earlier than we have been built-in with Snowflake and Sigma, connecting to over 225,000 belongings. We’re so proud of the outcomes,” Daniel shared.
This near-instant connection reworked information discovery at North, as soon as a chaotic expertise of leaping by means of a number of silos, instantly making it easy to navigate and perceive their information property.
Atlan began getting us this fast worth by means of information discovery. The best way I preserve enthusiastic about it was the early days of the web. You had entry to this huge quantity of data, nevertheless it was actually arduous to seek out. Then, search engines like google and yahoo made it simple to run a search and discover related content material. For us, Atlan grew to become Google for Knowledge.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance

Shifting past easy information discovery, Daniel’s group launched information glossaries, definitions, and complete phrases, enabling deeper dives into information, and using lineage to grasp upstream and downstream dependencies with ease.
With this precious context unlocked, their subsequent step was to ship it on to enterprise customers, who primarily eat information inside the Sigma, with out switching to different instruments.
“That’s the place Atlan’s Chrome Extension grew to become a game-changer,” Daniel shared.
Atlan’s Chrome Extension reworked information consumption inside Sigma. With context about their information belongings—dashboard descriptions, information definitions, tags, lineage, notifications, and upstream high quality alerts—now obtainable immediately in Sigma, customers not needed to soar between instruments to perform their duties.
Out there in a sidebar, Atlan’s Chrome Extension made this data immediately accessible, with out coaching or change administration.
“The initiative required no coaching,” Daniel defined. “As a result of it’s a sidebar and intuitively reveals this data, we’d simply add it, then customers have been robotically up and working, enhancing their effectivity, and instantly seeing the profit.”
Situation Decision for Engineers and Shoppers, Alike
With context about their information belongings made obtainable in Sigma, Daniel and his group started work to enhance the method of troubleshooting and speaking points associated to those belongings. Upon receiving a ticket, North’s engineering group as soon as spent vital time looking by means of Sigma to establish the belongings referenced within the request. With out a direct hyperlink between tickets and these belongings, decision would usually be delayed, and work can be duplicated.
“It was actually inefficient,” Daniel shared. “Typically even the identical engineers can be engaged on the identical undertaking, and so they didn’t even understand it as a result of a number of tickets have been submitted by a number of folks.”

By integrating the Atlan Chrome Extension with Jira and Slack, North’s information shoppers might elevate points immediately of their software of selection, with a hyperlink to particular belongings included robotically, permitting Knowledge Engineers to grasp when and the place points occurred.
For information shoppers in Sigma, this integration provided a complete historical past of all Jira tickets and Slack conversations regarding particular information belongings, and for engineers, a way of stopping duplicate tickets or a number of engineers engaged on the identical concern, and time financial savings by higher understanding related, previous points.
Eliminating duplicate work, or eliminating your engineers engaged on the identical undertaking with out understanding about it? These effectivity beneficial properties are large, and the financial savings add up actually shortly.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
Introducing Snowflake Dynamic Knowledge Masking
As a funds resolution supplier, North handles huge quantities of delicate monetary information. Whereas enhancements in information discovery and enrichment are essential, Daniel’s group realized the worth of those enhancements can be restricted to a small variety of trusted customers with out strong information governance and documentation securing these belongings.
To safe delicate information and implement stringent entry insurance policies, North’s information group selected to make the most of Dynamic Knowledge Masking with Snowflake, providing complete column-level masking for delicate information, and policy-based management for customers.
With a view to make the most of Dynamic Knowledge Masking, Daniel and his group started the method of figuring out particular information belongings that these insurance policies would apply to. Given the size and complexity of their information panorama, they acknowledged {that a} granular, asset-by-asset method can be not solely time-consuming, however doubtlessly error-prone. Looking for a approach to establish and safe these belongings programmatically, Daniel turned to Atlan.
“How do you discover and tag hundreds of belongings? You don’t Google it, you Atlan it. It’s actually easy,” Daniel defined.
Governing Hundreds of Belongings, on the Click on of a Button
Somewhat than painstakingly finding these belongings, then tagging them one-by-one, their group utilized Atlan Playbooks, rules-based bulk automations that might establish hundreds of belongings primarily based on chosen standards, then robotically apply actions, akin to including chosen tags and insurance policies.
By the point I added a filter, Atlan scanned our 225,000 belongings and nearly instantly discovered 45 matches. As I modified the filters so as to add new ones, it always up to date to indicate me what number of belongings meet that standards. Hours of handbook analysis and testing, earlier than Atlan, was transformed into a pair seconds.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance

Shortly figuring out hundreds of belongings to better-secure, Daniel’s group used Playbooks to construct workflows that might robotically apply the suitable tag to the suitable asset, then propagate that tag upstream, on the click on of a button. Then, with Atlan’s Two-way Tag Sync, these tags would function the inspiration for Dynamic Knowledge Masking at North, robotically making use of masking insurance policies primarily based on how and from whom information was queried.
By combining Atlan Playbooks, Two-way Tag Sync, and Automated Lineage with Snowflake Dynamic Knowledge Masking, North efficiently ruled hundreds of knowledge belongings in document time with a programmatic method, avoiding the painstaking work of figuring out, tagging, and recording insurance policies one-by-one throughout a 225,000-asset panorama.
With out Atlan tracing upstream and downstream, serving to us perceive potential publicity and implement insurance policies, this course of would have been difficult and really handbook. However with Atlan, you can’t solely hint information lineage and arrange the complexity, however you may see recognition and utilization metrics that assist prioritize the place efforts are wanted probably the most, or the place the largest influence may very well be made.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
Via this programmatic method, Daniel’s group affected a 700% improve in tagged belongings, considerably enhancing their safety and compliance, and paving the way in which for a big improve within the variety of their colleagues trusted to make use of information.
“We’ve used Atlan to spice up the pace and accuracy of our asset tagging by greater than 700% since implementation,” Daniel shared. “With the power to find information quicker, apply tags, and reverse sync that information again into Snowflake, we added greater than 2,000 governance belongings in underneath a yr. That’s simply the tip of the iceberg.”
Tens of millions in Worth, in Months
In lower than one yr of being outfitted with Atlan, Daniel and his group reworked the way in which North makes use of and governs its information, unlocking the potential for hundreds of thousands in worth by means of effectivity beneficial properties, value reductions, and enhanced danger mitigation.
By thoughtfully converging essential context about Snowflake and Sigma right into a user-friendly data base in Atlan, North’s technical and enterprise customers are projecting financial savings of $1.4 million per yr in effort by means of accelerated information discovery and decreased effort understanding lineage.
“That’s $1.4 million of duplicate work, handbook and tedious analysis. That’s time we will now spend on altering issues, versus attempting to navigate information prefer it’s the web in 1997,” Daniel shared.
And with built-in insights in Atlan, close to–immediately figuring out pointless spend of their Snowflake setting, Daniel and his group estimate an annual value financial savings of greater than $20,000 by deprecating greater than 10,000 idle belongings and inefficient queries.
“That financial savings was mainly handed to us on a silver platter with no additional work,” Daniel remarked.
Past value financial savings and effectivity beneficial properties, and existential to an organization that processes delicate monetary information, lies vital danger mitigation. By growing their tagged belongings by 700%, shortly and in bulk, North’s governance and safety improved nearly in a single day, to the tune of hundreds of thousands of {dollars} in decreased danger.
We’ve been in a position to scale back our danger and publicity by hundreds of thousands and hundreds of thousands of {dollars}.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
A 200% Improve in Self-service Analytics, with Room to Develop
Whereas these enhancements are spectacular, whether or not in information discovery, with context about their information belongings supporting a 200% year-over-year improve in self-service analytics adoption, or in Knowledge Governance, driving hundreds of thousands in danger mitigation, it’s the mixture of those packages that’s set to rework the way in which North makes use of information.
By affecting a leap ahead in the way in which that North manages entry management and ensures safety throughout an enormous information property, the way in which Daniel’s group defines a trusted consumer of knowledge is evolving and increasing considerably.
“Knowledge Governance gave us the arrogance to soundly and securely share extra information in Sigma,” Daniel defined.Now assured that probably the most delicate information is safe, appropriately tagged, and ruled by the suitable entry coverage, North can confidently provide information and self-service analytics capabilities to extra enterprise customers than ever earlier than, enhancing the already vital worth they’ve yielded from combining Atlan, Snowflake, and Sigma.
We have been in a state of near-paralysis attempting to manually decide who ought to see what. Using a mix of improved governance insurance policies, tags, and dynamic information masking, we have been in a position to make use of information with confidence. Because of the enhanced consumer expertise, mixed with the elevated information availability, we count on to proceed or exceed our self-service setting progress charges.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
Mere years after adopting Snowflake as the inspiration of their Fashionable Knowledge Stack, and fewer than a yr after adopting Atlan, North’s information property has reworked from, as Daniel described, a “Knowledge Desert” into an “Oasis.”
“Because the information by no means leaves our umbrella, there’s no extra flat recordsdata which might be shared,” Daniel defined. “There’s no extra a number of variations of the reality, and our information has a degree of confidence, leading to quicker and extra knowledgeable choices.”
Regardless of the unbelievable accomplishments of North’s information group, constructing self-service analytics and Knowledge Governance capabilities from scratch in document time, Daniel believes there’s nonetheless a lot extra to perform.
Within the months and years to come back, their information group is raring to make use of Atlan AI to simplify advanced queries into pure language, and speed up the enrichment of their information belongings. And by supporting a rising variety of Knowledge Stewards to independently share and doc data, a extra knowledgeable and empowered neighborhood of enterprise customers is rising.
Reflecting on their journey with Atlan, Daniel emphasised that past the suitable expertise, group, and technique lies an important ingredient: The suitable partnership.
One of the vital essential issues about Atlan has been the folks. They’re information people who have labored within the business, perceive what you’re going by means of, and perceive what you’re speaking about from the second you begin the dialog.”
Daniel Dowdy, Vice President, Knowledge Analytics & Governance
Photograph by Jonas Leupe on Unsplash
[ad_2]
The post North Drives Tens of millions in Worth by Governing Snowflake with Atlan appeared first on CreditLose.
]]>The post Securing Your API Keys in Google Colab appeared first on CreditLose.
]]>Working with APIs in Google Colab is a standard observe for information scientists, researchers, and builders. Nonetheless, dealing with API keys, that are basically passwords granting entry to those providers, requires cautious consideration. Immediately embedding API keys in your code or storing them as plain atmosphere variables inside your Colab notebooks poses vital safety dangers. Google Colab’s “Secrets and techniques” function presents a sturdy resolution to this downside, offering a safe and handy technique to handle delicate credentials. This complete information delves into the significance of defending API keys, the vulnerabilities of conventional strategies, and an in depth walkthrough of utilizing Colab Secrets and techniques successfully.
Studying Aims
- Learners will have the ability to securely retailer API keys and different delicate information utilizing Google Colab’s Secrets and techniques function.
- Learners will have the ability to retrieve and make the most of saved secrets and techniques inside their Colab notebooks with out exposing the precise values of their code.
- Learners will have the ability to combine secrets and techniques as atmosphere variables to be used with libraries that require this methodology of authentication.
- Learners will have the ability to apply greatest practices for managing secrets and techniques, together with naming conventions, entry management, and safe updating.
This text was revealed as part of the Information Science Blogathon.
Crucial Want for API Key Safety
API keys are like digital keys to varied providers, permitting your functions to work together with them. If these keys fall into the flawed palms, the results could be extreme:
- Unauthorized Entry and Utilization: Malicious actors might use your API keys to entry providers with out your consent, doubtlessly incurring surprising prices or exceeding utilization quotas.
- Information Breaches and Safety Compromises: In some circumstances, compromised API keys might grant entry to delicate information or enable unauthorized modifications to your accounts.
- Reputational Injury: Safety breaches can harm your fame and erode belief amongst customers and stakeholders.
Due to this fact, implementing strong safety measures to guard API keys is paramount.
Why Use Secrets and techniques?
Storing API keys instantly in your Colab notebooks or as commonplace atmosphere variables exposes them to a number of vulnerabilities:
- Publicity in Shared Notebooks: When you share your pocket book with collaborators or publish it publicly, your API keys develop into readily accessible to anybody who views the pocket book.
- Model Management Dangers: Committing notebooks containing API keys to model management programs like Git can inadvertently expose them to the general public, as these repositories are sometimes publicly accessible. Even non-public repositories could be susceptible if entry management just isn’t correctly configured.
- Troublesome Key Rotation: Altering API keys turns into a cumbersome course of if they’re embedded all through your code. You would want to manually replace each occasion of the important thing, growing the chance of errors and inconsistencies.
Introducing Google Colab Secrets and techniques: A Safe Answer
Google Colab’s Secrets and techniques function addresses these vulnerabilities by offering a safe and centralized technique to handle delicate data. Right here’s the way it enhances safety:
- Encrypted Storage: Secrets and techniques are encrypted and saved securely on Google’s servers, defending them from unauthorized entry.
- Granular Entry Management: You possibly can management which notebooks have entry to particular secrets and techniques, guaranteeing that solely approved notebooks can retrieve and use them.
- No Direct Publicity in Code: API keys are by no means instantly embedded in your pocket book code, eliminating the chance of unintentional publicity via sharing or model management.
- Simplified Key Rotation: Updating an API key is so simple as modifying the key worth within the Secrets and techniques panel. All notebooks utilizing that secret will robotically use the up to date worth.
Step-by-Step Information to Utilizing Colab Secrets and techniques
Right here’s how one can use secrets and techniques in Google Colab:
Step1: Entry the Secrets and techniques Characteristic
- Open your Google Colab pocket book.
- Within the left-hand sidebar, you’ll discover an icon that appears like a key. Click on on it to open the “Secrets and techniques” panel.
Step2: Create a New Secret
- Click on on “Add a brand new secret”.
- Give your secret a descriptive identify (e.g., “OPENAI_API_KEY”). Notice that the identify is everlasting and can’t be modified later.
- Enter the precise API key worth within the “Worth” discipline.
- Click on “Save”.
Step3: Grant Pocket book Entry
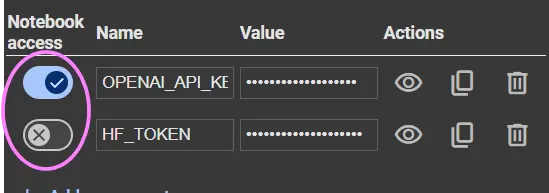
- As soon as the key is created, you’ll see a toggle swap subsequent to it.
- Ensure that the toggle is enabled to grant the present pocket book entry to the key.
Step4: Use the Secret in Your Pocket book
- To retrieve the key worth in your code, use the next code snippet:
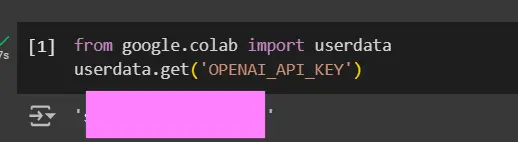
from google.colab import userdata
api_key = userdata.get('OPENAI_API_KEY')
- Exchange ‘OPENAI_API_KEY’ with the precise identify of your secret.
- The userdata.get() operate retrieves the key worth as a string. In case your secret is a quantity, you’ll have to convert it accordingly (e.g., int(userdata.get(‘MY_NUMBER’))).
Step5: Utilizing Secrets and techniques as Atmosphere Variables
- Many Python libraries anticipate API keys to be set as atmosphere variables. You possibly can simply obtain this utilizing the os module:

import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
# Now you should use the API key with libraries that depend on atmosphere variables # Instance: # import openai
# openai.api_key = os.getenv("OPENAI_API_KEY")
Finest Practices for Managing Secrets and techniques
Beneath we are going to look into the most effective practices for managing secrets and techniques:
- Significant Secret Names: Use descriptive and constant naming conventions to your secrets and techniques to simply establish and handle them.
- Common Entry Evaluation: Periodically overview which notebooks have entry to your secrets and techniques and revoke entry for notebooks that not require them.
- Cautious Secret Updates: When updating an API key, replace the corresponding secret worth within the Secrets and techniques panel. Keep away from deleting and recreating secrets and techniques except completely vital.
- Keep away from Printing Secrets and techniques: By no means print or show the precise secret worth in your pocket book output. It is a essential safety precaution.
- Precept of Least Privilege: Grant entry to secrets and techniques solely to the notebooks that completely want them. Keep away from granting broad entry except vital.
Conclusion
Utilizing Google Colab’s Secrets and techniques function is important for sustaining the safety of your API keys and different delicate data. By following the rules outlined on this article, you may considerably scale back the chance of unauthorized entry and make sure the integrity of your tasks. Implementing these greatest practices will contribute to a safer and environment friendly workflow when working with APIs in Google Colab.
Key Takeaways
- Immediately embedding API keys in Google Colab notebooks is a big safety danger. Sharing notebooks or committing them to model management can expose these delicate credentials.
- Google Colab’s Secrets and techniques function supplies a safe different for storing and managing API keys. Secrets and techniques are encrypted and accessed programmatically, stopping direct publicity in code.
- Secrets and techniques could be simply retrieved inside Colab notebooks utilizing the userdata.get() operate and built-in as atmosphere variables. This enables seamless use with varied libraries and APIs.
- Following greatest practices for secret administration, similar to utilizing descriptive names and commonly reviewing entry, is essential for sustaining safety. This ensures solely approved notebooks can entry vital credentials.
Ceaselessly Requested Questions
A. No. Secrets and techniques are saved securely by Google and should not included if you share your pocket book. Others might want to create their very own secrets and techniques with the identical names in the event that they need to run the code.
A. No, the identify of a secret can’t be modified after creation. When you want a special identify, you’ll need to create a brand new secret and delete the previous one.
A. Merely go to the Secrets and techniques panel, discover the key you need to replace, and alter the worth within the “Worth” discipline. The change will probably be mirrored in any notebooks that use that secret.
A. Whereas there’s no explicitly documented restrict, creating an extreme variety of secrets and techniques would possibly impression efficiency. It’s greatest to handle your secrets and techniques effectively and keep away from creating pointless ones.
A. No, deleting a pocket book doesn’t delete the related secrets and techniques. You have to manually delete secrets and techniques from the Secrets and techniques panel for those who not want them. This is a vital safety function to forestall unintentional information loss.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Hello there! I’m Himanshu Ranjan, and I’ve a deep ardour for information every little thing from crunching numbers to discovering patterns that inform a narrative. For me, information is extra than simply numbers on a display; it’s a software for discovery and perception. I’m all the time excited by the potential of what information can reveal and the way it can clear up real-world issues.
However it’s not simply information that grabs my consideration. I really like exploring new issues, whether or not that’s studying a brand new ability, experimenting with new applied sciences, or diving into subjects outdoors my consolation zone. Curiosity drives me, and I’m all the time searching for recent challenges that push me to assume in a different way and develop. At coronary heart, I consider there’s all the time extra to study, and I’m on a continuing journey to develop my data and perspective.
[ad_2]
The post Securing Your API Keys in Google Colab appeared first on CreditLose.
]]>The post 2025 Information Analytics Predictions appeared first on CreditLose.
]]>
(Zakharchuk/Shutterstock)
It’s that point of yr once more–time for predictions! We begin off the 2025 bonanza of forecasts, estimates, and prognostications with a subject that’s close to and pricey to our hearts right here at BigDATAwire: knowledge analytics.
The world has seen all kinds of patterns for analytics: knowledge lakes, knowledge warehouses, in-memory analytics, and embedded analytics. However in 2025, the usual for analytics would be the knowledge lakehouse, says Emmanuel Darras, CEO and Co-founder of Kestra, developer of an open-source orchestration platform.
“By 2025, over half of all analytics workloads are anticipated to run on lakehouse architectures, pushed by the price financial savings and suppleness they provide,” Darras says. “At present, firms are shifting from cloud knowledge warehouses to lakehouses, not simply to economize however to simplify knowledge entry patterns and scale back the necessity for duplicate knowledge storage. Giant organizations have reported financial savings of over 50%, a serious win for these with vital knowledge processing wants.”
One of many large drivers of the info lakehouse is the standardization of open knowledge codecs. That may be a development that may proceed to construct in 2025, predicts Adam Bellemare, principal technologist within the Know-how Technique Group at Confluent.

Lakehouses will proliferate in 2025, it has been predicted (FlorentinCatargiu/Shutterstock)
“Subsequent yr we are going to see a widespread standardization of open knowledge codecs, akin to Apache Iceberg, Delta Lake, and Apache Hudi,” says Bellemare. “This shall be pushed by a higher demand for interoperability, with enterprises seeking to seamlessly mix knowledge throughout totally different platforms, companions, and distributors. As enterprises prioritize entry to well timed, high-quality knowledge, open knowledge codecs will not be non-compulsory however crucial for companies to succeed. Those that fail to embrace these open requirements threat shedding a aggressive benefit, and those that undertake them will have the ability to ship a high-quality providing and real-time, cross-platform knowledge insights.”
Two of the most important backers of the info lakehouse are Snowflake and Databricks. However in 2025, folks will tire of the Snowflake/Databrick Struggle and look to federated IT for an advanced knowledge structure, says Andrew Madson, a technical evangelist at Dremio and professor of information and analytics at Southern New Hampshire and Grand Canyon universities.
“Central IT groups will proceed decentralizing tasks to enterprise items, creating extra federated working fashions,” Madson says. “In the meantime, monolithic architectures from main distributors like Snowflake and Databricks will combine further instruments aimed toward enhancing cost-efficiency and efficiency, creating hybrid ecosystems that steadiness innovation and practicality.”
Information modeling has wallowed in relative obscurity for years. In 2025, the observe can have its second within the solar, says Adi Polak, Confluent’s director of advocacy and developer expertise engineering.
Iceberg has enabled knowledge lakehouse unfold
“Information modeling has lengthy been the area of DBAs (database directors), however with the elevated adoption of open desk codecs like Apache Iceberg, knowledge modeling is a ability that extra engineers have to grasp,” Polak says. “For software improvement, engineers are more and more tasked with creating reusable knowledge merchandise, supporting each real-time and batch workloads whereas anticipating downstream consumption patterns. To construct these knowledge merchandise successfully, engineers should perceive how knowledge shall be used and design the best construction, or mannequin, that’s appropriate for consumption, early on. That’s why knowledge modeling shall be a necessary ability for engineers to grasp within the coming yr.
There’s one subject that shall be not possible to keep away from in 2025: AI (sure, we’ll have an AI 2025 predictions piece quickly). AI’s influence shall be felt in every single place, together with the info analytics stack, says Christian Buckner, SVP of analytics and IoT at Altair.
“As we speak, many enterprise leaders battle with realizing what inquiries to ask their knowledge or the place to search out the solutions,” Buckner says. “AI brokers are altering that by robotically delivering insights and proposals, with out the necessity for anybody to ask. This degree of automation shall be essential for serving to organizations unlock deeper understanding and connections inside their knowledge and empowering them to make extra strategic choices for enterprise benefit. it’s vital for companies to ascertain guardrails to manage AI-driven solutions and preserve belief within the outcomes.”
Whenever you mentioned “analytics,” it used to conjure pictures of somebody firing up a desktop BI software to work with a slice of information from the warehouse. My, instances have modified. Based on Sisense CEO Ariel Katz, 2025 will convey concerning the demise of conventional BI, which shall be changed with API-first and GenAI-integrated analytics in each app.
“In 2025, conventional BI instruments will turn out to be out of date, as API-first architectures and GenAI seamlessly embed real-time analytics into each software,” Katz says. “Information insights will circulate instantly into CRMs, productiveness platforms, and buyer instruments, empowering staff in any respect ranges to make data-driven choices immediately–no technical experience wanted. Corporations that embrace this shift will unlock unprecedented productiveness and buyer experiences, leaving static dashboards and siloed techniques within the mud.”

Embedded analytics shall be large in 2025, it’s been predicted (ZinetroN/Shutterstock)
Huge knowledge was large as a result of–properly, it simply was (belief us). However in 2025, the massive knowledge motion will open a brand new chapter by welcoming a relative of huge knowledge known as small knowledge, predicts Francois Ajenstat, the Chief Product Officer at Amplitude.
“The previous few years have seen an increase in knowledge volumes, however 2025 will convey the main focus from ‘large knowledge’ to ‘small knowledge,’” Ajenstat says. “We’re already seeing this mindset shift with massive language fashions giving method to small language fashions. Organizations are realizing they don’t have to convey all their knowledge to resolve an issue or full an initiative–they should convey the best knowledge. The overwhelming abundance of information, also known as the ‘knowledge swamp,’ has made it tougher to extract significant insights. By specializing in extra focused, higher-quality knowledge–or the ‘knowledge pond’–organizations can guarantee knowledge belief and precision. This shift in the direction of smaller, extra related knowledge will assist velocity up evaluation timelines, get extra folks utilizing knowledge, and drive higher ROI from knowledge investments.”
It’s at all times been cool to have high-quality knowledge. However in 2025, having high-quality knowledge will turn out to be a enterprise crucial, says Rajan Goyal, the CEO and co-founder of DataPelago.
“We’re seeing rising studies that LLM suppliers are scuffling with mannequin slowdown, and AI’s scaling regulation is more and more being questioned,” Goyal says. “As this development continues, it should turn out to be accepted data subsequent yr that the important thing to growing, coaching and fine-tuning simpler AI fashions is not extra knowledge however higher knowledge. Particularly, high-quality contextual knowledge that aligns with a mannequin’s supposed use case shall be key. Past simply the mannequin builders, this development will place a higher onus on the tip prospects who possess most of this knowledge to modernize their knowledge administration architectures for right this moment’s AI necessities to allow them to successfully fine-tune fashions and gas RAG workloads.”
Information silos are like mushrooms: They seem naturally with none human enter. However in 2025, companies might want to get on high of the expansion of information silos in the event that they need to succeed, says Molly Presley, the SVP of worldwide advertising for Hammerspace.

These aren’t mushrooms — they’re knowledge silos (Aleutie/Shutterstock)
“In 2025, breaking down knowledge silos will emerge as a essential architectural concern for knowledge engineers and AI architects,” Presley writes “The flexibility to combination and unify disparate knowledge units throughout organizations shall be important for driving superior analytics, AI, and machine studying initiatives. As the quantity and variety of information sources proceed to develop, overcoming these silos shall be essential for enabling the holistic insights and decision-making that fashionable AI techniques demand.”
Managing consumer entry to knowledge generally looks like every thing in every single place unexpectedly. As a substitute of combating that worker- and data-sprawl, groups in 2025 will learn to extra successfully harness instruments like streaming knowledge to make themselves extra productive, predicts Arcitecta CEO Jason Lohrey.
“The rise of distant work and geographically distributed groups has modified how companies function,” Lohrey says. “Actual-time knowledge streaming permits organizations to file occasions and share reside feeds globally, enabling staff to collaborate on steady knowledge streams with no need to be bodily current. This development will seemingly speed up in 2025 as extra firms undertake instruments that facilitate seamless broadcasting and knowledge distribution. By enabling real-time collaboration throughout a distributed workforce, companies can scale back journey prices, improve effectivity, and make faster, extra knowledgeable choices. The worldwide attain of information streaming expertise will broaden, permitting organizations to faucet right into a wider expertise pool and create extra dynamic and versatile operational buildings.”
[ad_2]
The post 2025 Information Analytics Predictions appeared first on CreditLose.
]]>